
Lyra is a workflow engine for provisioning and orchestrating cloud native infrastructure.
Setting up Lyra
Using Lyra
Writing a Lyra workflow in YAML
Running Lyra in Kubernetes controller mode
Reference
Architecture
Components
Here’s a high-level overview of the components within Lyra.
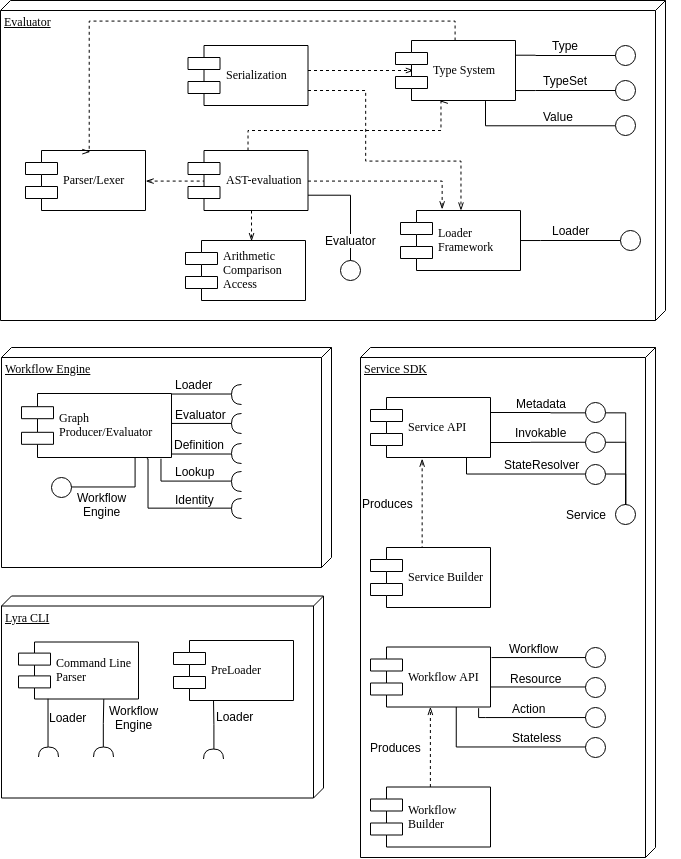
Manifests
A manifest will typically consist of one workflow definition written in a declarative or compiled language of choice. That workflow defines the desired state of an infrastructure or piece of an infrastructure.
Languages
The currently supported languages are Puppet, Go, TypeScript and YAML. Manifests written in Go must either be compiled and provided as a service or executed using a Lyra link that performs a go run on the source.
CLI
The Lyra Command Line Interface. Provides commands like apply, validate, and version.
Workflow Engine
Performs evaluation of workflow step definitions using services. Services and definitions are obtained from the Loader.
Loader
Loads and manages all services, workflow steps, value types, and functions available to the system.
Language Front-end
Parses workflow manifests written in a specific language into step definitions that the workflow engine can understand. Executes imperative steps (actions) on demand using an evaluator native to the language.
Lookup
A Hiera 5 compatible framework for looking up various values such as environment settings, command line options, secret credentials, and configuration values. A workflow or a step can declare that input should be fulfilled by lookup.
The lookup framework is easy to extend with new functionality by adding special backend functions tailored to read from a file or use vault, k8s, etc.
Identity Storage
A persistent store that maps Lyra internal step identifiers to external resource identifiers.
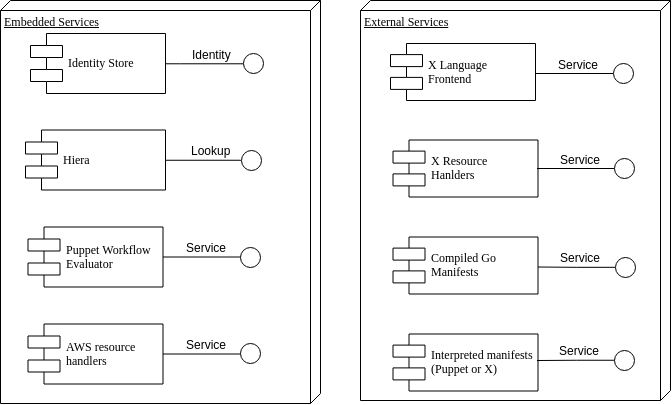
Service
An external process described by a service definition. Examples of services are:
-
Identity - The Identity Storage
-
Aws - Provides handlers for a number of Aws resource types
-
Puppet-Workflow - Language Front-end for Puppet. Produces step definitions from Puppet manifests
Principles
Dynamically Typed Values
The Lyra architecture relies heavily on dynamically typed values. A dynamically typed value can hold data of any kind and is described using a dynamic type. Important features of dynamically typed values are:
-
Efficiently serialized/deserialized without loss of type information.
-
Reflection to and from Go values.
-
Readable string representation.
-
Well defined comparison and arithmetic.
-
Type assertion. Enables checks for type correctness.
-
Reflective API.
-
Unified way for accessing properties and invoking methods.
-
Immutability, which eliminates a lot of potential concurrency problems.
The Type system used in Lyra is the same as in Puppet. This vouches for future integrations that communicate using complex data types (RichData).
Federated Loaders
The Loader framework provided by the pcore module is used to form a loader hierarchy in Lyra. The basic loader hierarchy finds all the well-known types such as String, Integer, Array, etc. It also allows for new types and functions to be added. Lyra then adds a customized loader that finds services and definitions.
All types, functions, workflow steps, etc. are loaded on demand. The loader finds many things by looking for named files in well known directories such as “workflows” and “types”. When a user invokes the Lyra CLI with an apply command with the name of a manifest, the loader will look for a file with that name that has a known extension such as “.yaml” or “.pp”. If found, it will load it and hand it over to the workflow engine for execution.
Serialization
The ability to send complex data structures between processes is very important to Lyra since much of its tasks are performed using services. All communication with such services are currently based on Protocol Buffers over gRPC. The evaluator provides efficient bi-directional conversion between dynamically typed values and the Data protocol buffer provided by the Lyra *data-protobuf *module, enabling data of arbitrary complexity to be sent over the wire in a type-safe and efficient manner.
Declarative or Imperative Programming
Lyra covers both programming models by providing specializations of a Step, such as Resource, which is pure declaration of a desired state.
Lyra also allows generic Action steps that are very similar to functions. I.e. code that is called with parameters and returns values. Such actions can do virtually anything. When controlled by Guards they can mimic state-changes that are not easily expressed using resources.
Ordering
Lyra makes ordering easy without enforcing a specific model onto the user. As mentioned, all order of execution can be determined by the workflow engine, either by just looking at the input and output declarations of activities contained in a workflow, or by running all activities sequentially.
Order isn’t applicable within individual steps because they are either a declaration of state, a block of code to execute, or a workflow in which case it manages its own order internally. If it is code, then that code is in charge of its own actions. The workflow engine treats an invocation of the code as one-off execution of something opaque.
A special collect step enables the declaration of a step that should be invoked multiple times. The declared step will run multiple times, each time with a different value of a given variable or variables. The invocations will happen in parallel. Lyra has two collect steps, “times” and “each”.
CRUD
Create, read, update and delete are distinct functions that Lyra aims to provide out of the box. In many cases, all of them can be performed using one single workflow that declares a set of resources and a set of sane rules. The CRUD methods are:
-
Create - create an external resource based on a desired state.
-
Read - collect data and optionally report diffs between the desired and actual state.
-
Update - update an external state with new data.
-
Delete - delete the external state.
It is expected that more elaborate schemes will be architected and implemented. There will however still be cases where automated rules do not apply. In Lyra, this is solved by writing special workflows for the non-default situations.
Go Modules
Lyra is built using Go modules. The suite of repositories it uses can be found at the Lyra Project at GitHub. Here’s a brief description of each module (a module maps 1-1 to git a repository).
lyra
Contains the Lyra CLI, Lyra Loader, and a suite of resource handlers.
terraform-bridge
Makes Terraform providers usable to Lyra as resource handlers.
servicesdk
Lyra Software Development Kit. Intended for authors of new Lyra services. It provides what’s needed to register new services, handles, definitions, and types to the Go author. An sdk will be provided for each of the supported languages.
hiera
A Hiera 5 compatible system used to lookup data from various sources such as yaml files, environment variables, or databases.
pcore
Manages the Puppet Type System, dynamic typed values, Puppet compatible serialization of RichData, and bidirectional reflection between Go and Puppet types and values.
wfe
The Workflow Engine.
semver
An implementation of semantic version and version ranges. The implementation follows the Semantic Versioning Specification for versions and the Npm Version Range Specification for version ranges.
issue
Formalized Warning and Error reporting.
data-protobuf
Protobuf definition for transferring generic Data structures.
yaml-workflow
The YAML Front-end
puppet-workflow
The Puppet Language Front-end
puppet-parser
Parser used when parsing types and manifests. The parser is a full implementation of the Puppet DSL.
puppet-evaluator
The Manages the evaluation of ASTs (Abstract Syntax Trees) produced by the Puppet Parser.
puppet-spec
Contains lots of tests written in Puppet Spec language for parser, evaluator, and hiera modules.